You already know Predixsport publishes probability distributions for NBA, football and tennis matches — full PDFs, CDFs, calibration data, the works. The question this article tries to answer is a much simpler one: which of the three ways to get that data into your workflow actually fits you.
There are now three:
- The Claude MCP connector — a quick one-time setup on a computer, then ask questions in plain English inside Claude, phone included.
- The REST API — same data, JSON over HTTPS, for code.
- The JSON / CSV download — one match at a time, free with a Google sign-in.
They look interchangeable from the outside. They are not. Each one is built for a different reader, and picking the wrong one is the difference between "this is great" and "why doesn't this do what I want."
The short version
If you spend your day inside Claude — desktop, web, or the iOS and Android apps — and you want sports analysis to live there too, use the connector.
If you're writing code (Python, Node, R, whatever) and Predixsport's data is one piece of a larger pipeline you're building, use the API.
If you want to read tonight's match once, on your own, with no setup, use the download on any match analysis page.
That's the decision. The rest of this article is just why, so you can sanity-check yourself before committing.
"Why not just ask Claude to read your website?"
This is the first question I get, so let me address it head-on.
You can absolutely ask Claude (or any agentic browser) to open predixsport.com/nba_predictions
and read it. It will sort-of work. It will also miss things you care about.
The page you see in a browser is rendered for humans. Probabilities are rounded to one decimal. Distribution charts are images — Claude sees pixels, not the underlying PDF. The calibration history lives on a different page. The model identifier lives in a tooltip. Stitching all of this together into a coherent answer is exactly the kind of thing browser-based agents do badly.
The MCP connector skips that whole problem. When Claude calls the Predixsport tool, it receives the same data the rendering pipeline starts from: the raw probability vector, the full distribution arrays, the model identifier, the prediction timestamp, the calibration history. It can answer follow-ups like "how confident was the model about this matchup a week ago" because it's asking the database directly, not re-parsing a webpage.
There is also a practical cost. Each HTML fetch eats your Claude token budget. The MCP tool calls don't — the response payloads are compact JSON, sized for an LLM to consume.
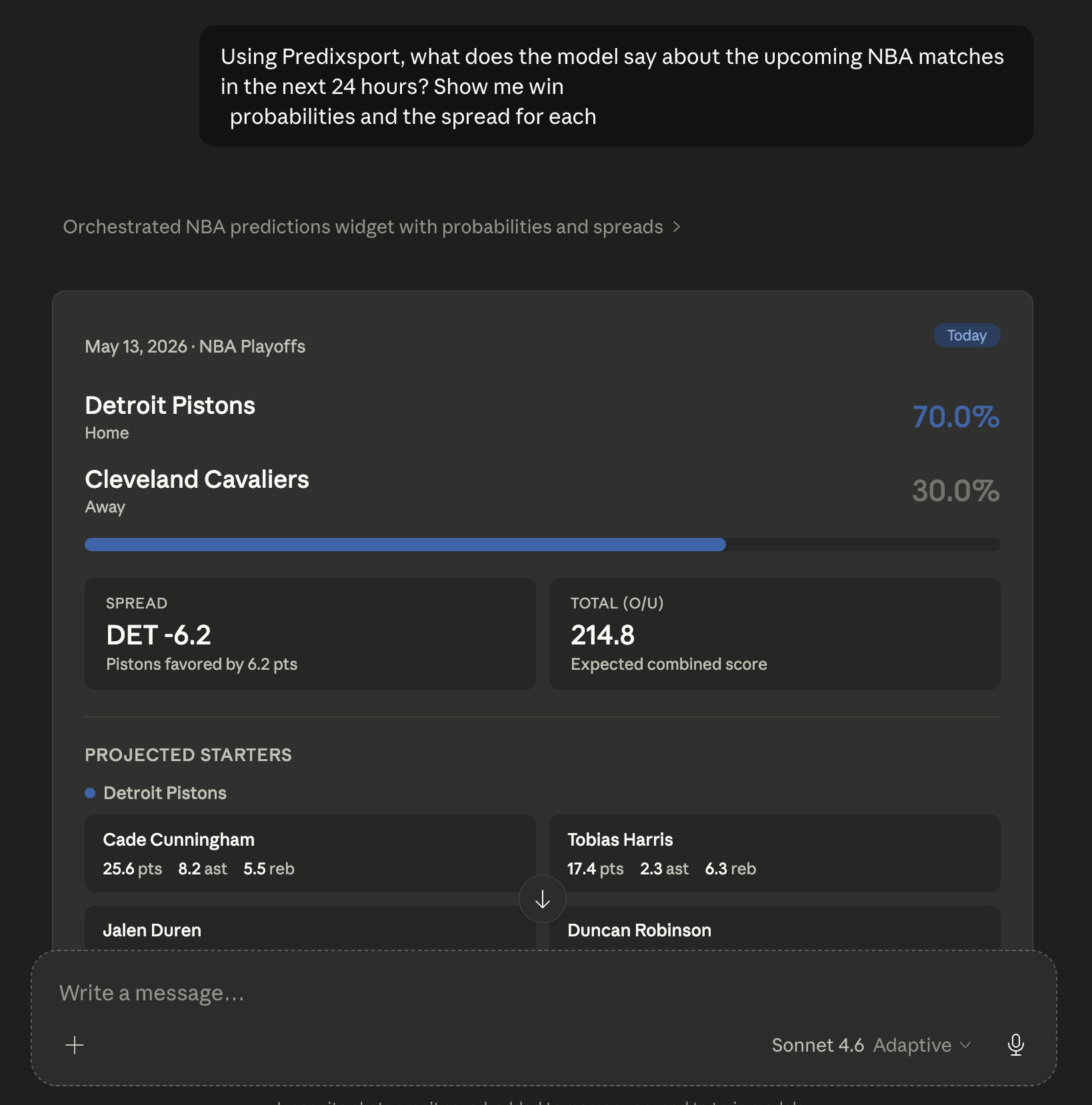
"Why not just download the JSON or CSV?"
The download has its place. It's fine if you're doing a one-off analysis: pulling tonight's NBA file, asking Claude to compare it to your fantasy lineup, putting the laptop away.
It stops being fine the day after.
Predictions update at multiple points. Model retraining shifts the underlying distributions. NBA inference, in particular, only fires a few hours before tip-off, because starting lineups and injury reports don't exist before then. A file you downloaded yesterday morning may show no matches at all even though three are about to start. The connector pulls fresh data when you ask, so the freshness problem goes away.
There is also a workflow piece. With the connector you don't have to drive the conversation manually. Claude's scheduled prompts (available on Pro and Max plans) can run a question on a recurring schedule — for example, every morning at nine, summarising today's matches against the model's calibration history. You read the summary over coffee. You did not click anything.
"Every weekday at 09:00, list the upcoming NBA games for today with the Predixsport win probability, total points expected value, and the predicted point differential. Flag the games where the prediction is high-confidence but the distribution is unusually wide. Keep it under 200 words."
"How is this different from your API?"
The connector runs on top of the API. Same endpoints, same response format, same data. The choice is about audience, not about content.
The API is for people who write code. Python, Node, Go, Streamlit dashboards, model stacks, automated pipelines — go API. You get raw JSON, you control concurrency, you set up your own caching and observability. You'll need a key. You'll write the integration once. After that, full control.
The connector is for people who don't want to write that integration. You install it once in Claude. There is no SDK to learn, no rate-limit handler to code, no JSON parsing to think about. Claude takes care of the call and turns the response into prose, charts, and follow-up questions. The cost is that you are tied to Claude's interface — which is precisely the point if Claude is already where your other work happens.
The way I think about it: the API is what we sell to engineers; the MCP connector is what we sell to everyone else who lives in an AI chatbot.
What MCP makes possible that nothing else does
I built the MCP connector second, after the API. The reason was simple: once it shipped, something became possible that's awkward with anything else — one conversation, multiple data sources.
A concrete example. You play fantasy basketball. Your roster lives in some fantasy app — Yahoo, ESPN, whatever. You keep season notes in a personal documents app. With MCP servers from each source connected to your Claude account, you can have a single conversation that goes:
"For tonight's slate: which of my Yahoo players is starting? Cross-reference with Predixsport's projections for points, rebounds and assists. Flag the ones whose distribution is unusually wide. Pull my notes from last week on the same matchups."
Claude reads all three sources, in one back-and-forth, and you don't open three apps. That's not a feature any of those sources can deliver on its own. It is what the protocol — MCP — was designed for.
The same idea scales to scheduled briefings. A recurring prompt, automated, asking Claude to summarise upcoming games against the model's calibration history and any relevant news. Claude orchestrates the calls; the connectors do the data fetching; you read one answer. No app-switching, no copying values from one tab into another.
Fantasy managers planning lineups, sports journalists looking for probability-backed angles for a preview, broadcasters wanting a quick read on tonight's games, people who care about how a forecast was assembled — that is who this layer is for.
What it costs, honestly
Predixsport itself is free to use right now. Sign in with Google, generate a key from /api-access, paste it into the Claude connector configuration, done.
Claude has Free, Pro and Max tiers; all three support custom MCP connectors. The Free tier is limited to one connector at a time (you'd be using yours for us); Pro and above don't have a documented cap. Pricing for Claude itself is at claude.com/pricing — Predixsport does not earn anything from that link.
No third-party trackers stitched into the connector. The methodology page explains what gets logged on our side — short answer: API calls hit a per-key counter for rate-limiting and a minimal audit log for operational issues. That's it.
Set it up
If you've read this far, you probably already know which option you want. If it's the connector, the setup walkthrough is on /mcp-setup — copy and paste, about four minutes. One thing to know up front: that one-time setup has to be done on a computer. Claude only lets you add a connector from claude.ai in a desktop browser (or the desktop app), not from the iOS or Android apps — so doing it on a phone just bounces you into the Claude app with nowhere to add it. Set it up once on a computer and Predixsport then shows up in Claude on your phone automatically. If you change your mind later, the API key is on the same login and the JSON/CSV download is on every match page.
If you try this and something doesn't behave the way the article promised, the contact form goes straight to me. I read every message — it is still that kind of operation.
Pick your path
Connector, API, or download — the data is the same; only the layer changes.